

Amazon Web Services Technical Essentials
Amazon Web Services

Hello there! I am a full-stack software developer with a passion for front-end development. With years of experience under my belt, I bring a unique combination of technical skills and creative vision to every project I work on. I am dedicated to delivering visually appealing and intuitive interfaces that provide an exceptional user experience. Whether it's building responsive web applications or crafting complex full-stack applications, I am committed to delivering high-quality, scalable, and maintainable code. I am always seeking new challenges and opportunities to grow and stay on the cutting edge of the latest industry trends and technologies. I am excited to share my insights and expertise with you on this platform. Let's learn and grow together!
Introduction to Amazon Web Services
What is Amazon
Amazon is one of the world's largest and most successful online retail companies, with a history that spans over two decades. The company was founded in 1994 by Jeff Bezos, who started Amazon as an online bookseller. Over the years, Amazon has expanded its product offerings to include a wide range of items, including electronics, clothing, food, and more.
In the early years, Amazon faced fierce competition from established brick-and-mortar retailers, as well as other online companies. However, the company's focus on customer service, fast shipping, and a vast selection of products helped it to grow rapidly. In 2002, Amazon introduced its Prime membership program, which offered customers free two-day shipping and other benefits in exchange for an annual fee. This program proved to be incredibly popular and helped to further solidify Amazon's position as a leading online retailer.
In recent years, Amazon has expanded into new markets and industries, including cloud computing, artificial intelligence, and streaming media. The company has also acquired several companies, including Whole Foods Market and Twitch, and has invested in a variety of new ventures. Today, Amazon is one of the world's most valuable companies and continues to shape the future of retail and technology.
What is cloud
Cloud computing is a model of delivering computing services over the internet, on-demand, and on a pay-per-use basis. It refers to a network of remote servers hosted on the internet to store, manage, and process data, rather than a local server or a personal computer.
With cloud computing, users can access these computing resources from anywhere with an internet connection, without having to worry about the maintenance, setup, or management of the underlying infrastructure. This allows for more efficient and cost-effective computing, as well as increased scalability and accessibility.
Examples of cloud computing services include infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). IaaS provides access to computing infrastructure, such as virtual machines and storage. PaaS provides a platform for developing and deploying software applications. SaaS delivers software applications over the internet, allowing users to access the software through a web browser or other client.
Advantages of cloud computing
Pay as you go
Instead of investing in data centers and hardware before you know how you are going to use them, you pay only when you use computing resources, and pay only for how much you use.
Benefit from massive economies of scale
By using cloud computing, you can achieve a lower cost than you can get on your own. Because usage from hundreds of thousands of customers is aggregated in the cloud, AWS can achieve higher economies of scale, which translates into lower pay as-you-go prices.
Stop guessing capacity
Eliminate guessing on your infrastructure capacity needs. When you make a capacity decision prior to deploying an application, you often end up either sitting on expensive idle resources or dealing with limited capacity. With cloud computing, these problems go away. You can access as much or as little capacity as you need, and scale up and down as required with only a few minutes notice.
Increase speed and agility
IT resources are only a click away, which means that you reduce the time to make resources available to your developers from weeks to minutes. This results in a dramatic increase in agility for the organization, since the cost and time it takes to experiment and develop is significantly lower.
Realize cost savings
Companies can focus on projects that differentiate their business instead of maintaining data centers. Cloud computing lets you focus on your customers, rather than on the heavy lifting of racking, stacking, and powering physical infrastructure. This is often referred to as undifferentiated heavy lifting.
Go global in minutes
Applications can be deployed in multiple Regions around the world with a few clicks. This means that you can provide lower latency and a better experience for your customers at a minimal cost.
AWS Global Infrastructure
Redundancy in cloud computing refers to the practice of providing multiple copies of data or resources in order to ensure that they are available even in the event of a failure or outage. The goal of redundancy is to improve the reliability, availability, and resiliency of cloud computing systems.
There are several types of redundancy that can be implemented in cloud computing:
Data redundancy: Multiple copies of data are stored in different locations, so that if one copy becomes unavailable, another copy can be used. This can be achieved through techniques such as mirroring, replication, and backup.
Network redundancy: Multiple network connections are used to ensure that there is always a working connection, even if one fails. This can be achieved through the use of multiple network interfaces, load balancing, and failover.
Hardware redundancy: Multiple hardware components are used to ensure that the system continues to function even if one component fails. For example, a cloud service provider might use redundant power supplies, redundant network connections, and redundant storage arrays.
Location redundancy: Data and resources are stored in multiple geographic locations to ensure that they are available even in the event of a disaster or outage in one location.
By implementing redundancy, cloud computing service providers can ensure that their systems are available and resilient, even in the face of failures or outages. This provides peace of mind to users who rely on cloud computing services for their critical applications and data.
Region
Regions are geographic locations worldwide where AWS hosts its data centers. AWS Regions are named after the location where they reside. For example, in the United States, the Region in Northern Virginia is called the Northern Virginia Region, and the Region in Oregon is called the Oregon Region.
AWS currently has multiple regions worldwide, including North America, South America, Europe, Asia Pacific, and Middle East and Africa. Each region is designed to operate independently, so that customers can run their applications and store their data in a region that is closest to their users, reducing latency and increasing performance.
Each AWS Region is associated with a geographical name and a Region code.
Here are examples of Region codes:
us-east-1: The first Region created in the eastern US area. The geographical name for this Region is N. Virginia.
ap-northeast-1: The first Region created in the northeast Asia Pacific area. The geographical name for this Region is Tokyo.
Choose the Right AWS Region
Choosing the right AWS region is an important decision as it affects the performance, availability, and compliance of your applications and data. Here are a few key factors to consider when choosing an AWS region:
Latency: Latency refers to the time it takes for data to travel from the source to the destination. Choosing a region that is closer to your users can reduce latency and improve the performance of your application.
Data residency: Some industries and countries have strict data residency requirements, which dictate where customer data must be stored. AWS provides multiple regions around the world, allowing customers to store their data in a location that meets their data residency requirements.
Compliance: Certain industries have regulatory compliance requirements, such as PCI DSS, HIPAA, or SOC, that must be met when storing and processing data. AWS provides a number of certifications and accreditations to help customers meet these requirements.
Cost: AWS pricing varies by region, so it is important to consider the cost of storing and processing data in a specific region.
Service availability: AWS offers a variety of services, and not all services are available in all regions. Before choosing a region, it is important to ensure that the services you need are available in that region.
By considering these factors, you can choose the right AWS region that meets the specific needs of your application and data. You can also use the AWS Global Infrastructure map to explore the availability of AWS services by region.
Availability Zones

Inside every Region is a cluster of Availability Zones (AZs). An AZ consists of one or more data centers with redundant power, networking, and connectivity. These data centers operate in discrete facilities in undisclosed locations. They are connected using redundant high-speed and low-latency links.AZs also have a code name. Since they are located inside Regions, they can be addressed by appending a letter to the end of the Region code name. For example:
us-east-1a: An AZ in us-east-1 (N. Virginia Region)
sa-east-1b: An AZ in sa-east-1 (São Paulo Region)
Therefore, if you see that a resource exists in us-east-1c, you can infer that the resource is located in AZ c of the us-east-1 Region.
Scope AWS services
Amazon Web Services (AWS) provides a broad set of cloud computing services, including computing, storage, and database services, as well as security and content delivery services. Here is a list of some of the most commonly used AWS services:
Amazon EC2 (Elastic Compute Cloud) - scalable computing capacity in the cloud
Amazon S3 (Simple Storage Service) - object storage with industry-leading scalability and durability
Amazon RDS (Relational Database Service) - managed relational database service for MySQL, PostgreSQL, Oracle, SQL Server, and MariaDB
Amazon DynamoDB - fast and flexible NoSQL database service for all applications
Amazon VPC (Virtual Private Cloud) - logically isolated network within the AWS Cloud
Amazon SNS (Simple Notification Service) - publish/subscribe messaging and mobile notifications
Amazon Lambda - run your code without thinking about servers
Amazon CloudFront - global content delivery network (CDN) service
Amazon CloudWatch - monitor resources and applications
Amazon IAM (Identity and Access Management) - manage access to AWS services and resources.
This is by no means an exhaustive list, as AWS offers many other services as well, including analytics, machine learning, security, and more.
Maintaining Resilience
Maintaining resiliency refers to the ability of a system or application to remain available and functioning even in the face of failures or disruptions. There are several strategies that can be used to maintain resiliency in a cloud environment such as Amazon Web Services (AWS). Here are some best practices to help maintain resiliency in AWS:
Use multiple availability zones: AWS provides multiple isolated locations within a region, known as availability zones, which can be used to create highly available and resilient applications.
Implement Auto Scaling: Auto Scaling automatically adjusts the number of EC2 instances in your application based on demand, helping you maintain application availability and scale resources to meet changing conditions.
Use Load Balancing: Load balancing distributes incoming application traffic across multiple EC2 instances, improving application availability, fault tolerance, and scalability.
Backup and disaster recovery: Regularly backup your data and implement a disaster recovery plan to ensure that your critical data is protected and can be recovered in the event of a failure.
Use managed services: AWS provides managed services, such as Amazon RDS and DynamoDB, that can help you reduce the operational burden of managing databases and improve resiliency by automatically handling tasks such as failover, replication, and backups.
Monitoring and alerting: Use AWS tools, such as CloudWatch, to monitor your application and set up alerts to be notified of any potential issues before they become critical.
By following these best practices, you can help ensure that your applications are highly available and resilient even in the face of failures or disruptions.
Interacting with AWS
There are several ways to interact with Amazon Web Services (AWS), but here are the three main methods:
AWS Management Console: The AWS Management Console is a web-based graphical user interface that provides access to AWS services. It is the simplest way to interact with AWS and is well suited for individuals or small teams who need to perform basic operations, such as launching instances, creating storage buckets, or setting up security groups.
AWS Command Line Interface (CLI): The AWS CLI is a command line interface that provides a unified tool for managing AWS services. It enables you to perform AWS tasks from the command line, automate AWS tasks using scripts, and integrate AWS services into your existing workflow.
AWS SDKs: AWS provides software development kits (SDKs) for several programming languages, including Java, .NET, PHP, Python, Ruby, and more. The AWS SDKs provide libraries and tools for building applications that use AWS services, allowing you to interact with AWS using your preferred programming language.
Each of these methods of interaction has its own strengths and weaknesses, and the best choice for you will depend on your specific needs and requirements. For example, the AWS Management Console is well suited for individuals who need a simple and user-friendly interface, while the AWS CLI and SDKs are well suited for developers who need to automate tasks or integrate AWS into their existing applications.
Security and the AWS Shared Responsibility Model
The AWS Shared Responsibility Model is a key aspect of security in the Amazon Web Services (AWS) cloud computing platform. It outlines the responsibilities of both AWS and the customer in ensuring the security of data, applications, and infrastructure in the cloud.
According to the model, AWS is responsible for the security of the underlying infrastructure that powers the cloud platform, including the physical and network security of data centers, and the security of the virtual infrastructure, such as the hypervisor, storage, and networking components.
Customers, on the other hand, are responsible for the security in the cloud. This includes securing their own applications and data, implementing network security, and controlling access to resources through identity and access management (IAM) tools. Customers are also responsible for ensuring the security of their own workloads, such as securing the operating system and applications running on Amazon Elastic Compute Cloud (EC2) instances or using encryption to secure data stored in Amazon Simple Storage Service (S3) buckets.
In summary, the AWS Shared Responsibility Model provides a clear division of responsibilities between AWS and customers to ensure the security of cloud computing services. By taking advantage of the security features provided by AWS, while also properly securing their own applications and data, customers can take full advantage of the benefits of cloud computing while maintaining the necessary level of security for their organizations.
Protect the AWS Root User
The AWS root user is the main administrative account for an AWS account, and it has full permissions to access and manage all resources within the account. Therefore, it is important to protect the AWS root user and limit access to it.
Here are some best practices for protecting the AWS root user:
Enable Multi-Factor Authentication (MFA): Requiring an MFA device to access the root user can provide an additional layer of security and prevent unauthorized access to your AWS account.
Use IAM Users: Instead of using the root user, it is recommended to use IAM users for everyday activities. IAM users can have specific permissions assigned to them, allowing you to have fine-grained control over the actions they can perform within your AWS account.
Set up a Strong Password Policy: The password policy for the AWS root user should be strong and include a mix of uppercase and lowercase letters, numbers, and special characters. Consider using a password manager to generate and store secure passwords.
Use AWS Organizations: AWS Organizations allows you to centralize multiple AWS accounts into a single management structure. You can then use consolidated billing and security features to manage multiple AWS accounts and users.
Monitor AWS CloudTrail: AWS CloudTrail is a service that logs all API calls made within an AWS account. You can use CloudTrail to monitor the activities of the root user and detect any suspicious activity.
Regularly Review Access Logs: Regularly reviewing access logs can help you identify any unauthorized access attempts to your AWS account, including access attempts to the root user.
By following these best practices, you can help ensure the security of your AWS root user and protect your AWS environment.
Authentication and Authorization
Authentication and authorization are two related but distinct concepts in computer security.
Authentication is the process of verifying the identity of a user, device, or system. It is typically achieved through the use of credentials, such as a username and password, smart card, or biometric data. The goal of authentication is to ensure that only authorized entities are granted access to resources.
Authorization, on the other hand, is the process of granting or denying access to specific resources based on a user's authentication. It involves determining what actions a user is allowed to perform, such as reading, writing, or executing a specific file, accessing a specific network resource, or performing a specific operation within an application.
In other words, authentication establishes the identity of the user, while authorization determines what the user is allowed to do with the resources they have been granted access to.
Both authentication and authorization are important components of a comprehensive security plan and are commonly used to secure computer systems, applications, networks, and data. Implementing robust authentication and authorization protocols can help ensure that only authorized users are able to access resources and perform actions, helping to protect sensitive information and maintain the integrity of systems.
AWS Identity and Access Management
Amazon Web Services (AWS) Identity and Access Management (IAM) is a service that enables you to securely control access to AWS resources. IAM provides you with the ability to create and manage users, groups, and permissions, allowing you to implement the principle of least privilege, which means giving users only the minimum access they need to perform their job.
Here are some of the key features of AWS IAM:
User Management: You can create, manage, and delete IAM users, and assign them passwords or access keys. You can also grant or revoke permissions for users as needed.
Group Management: You can create IAM groups, which allow you to manage permissions for multiple users at once.
Role Management: You can create and manage AWS IAM roles, which are a type of IAM identity that you can use to grant permissions to AWS services, applications, or resources.
Policy Management: You can create and manage policies, which are collections of permissions that define what an IAM user, group, or role can do in an AWS account.
Multi-Factor Authentication: You can use IAM to require multi-factor authentication (MFA) for privileged users, such as AWS administrators.
Access Management: You can use IAM to control access to AWS resources by creating and managing resource-based policies that are associated with individual resources, such as Amazon S3 buckets or Amazon EC2 instances.
By using AWS IAM, you can enforce the principle of least privilege, reduce the risk of unauthorized access to AWS resources, and help ensure the security and compliance of your AWS environment.
Role-Based Access in AWS
Role-based access is an important concept in AWS Identity and Access Management (IAM). It refers to the practice of granting permissions to AWS resources based on the role a user performs, rather than based on the identity of the user.
In AWS IAM, you can create and manage roles, which are a type of IAM identity that you can use to grant permissions to AWS services, applications, or resources. Roles are associated with policies, which define the actions the role is allowed to perform and the resources it can access.
Here are some common use cases for role-based access in AWS:
EC2 Instance Roles: You can use EC2 instance roles to grant permissions to an EC2 instance so that it can access other AWS resources, such as an Amazon S3 bucket, without requiring long-term AWS credentials.
Cross-Account Access: You can use roles to grant access to AWS resources in one AWS account to users or applications in another AWS account. This can be useful for scenarios where one organization needs to access resources in another organization's AWS account.
Third-Party Applications: You can use roles to grant access to AWS resources to third-party applications, such as a cloud-based backup solution, without exposing long-term AWS credentials.
Service Roles: You can use roles to grant permissions to AWS services, such as AWS Lambda, to access other AWS resources, such as an Amazon S3 bucket, on your behalf.
By using role-based access in AWS IAM, you can improve the security and manageability of your AWS environment. Roles can be assigned and revoked as needed, allowing you to enforce the principle of least privilege, which means giving users only the minimum access they need to perform their job.
Compute as a Service
Compute as a Service" (CaaS) is a type of cloud computing service that provides customers with access to computing resources, such as virtual machines, containers, and other resources, over the internet. With CaaS, customers do not have to purchase, maintain, or manage their own physical hardware, as the infrastructure and resources are provided by the service provider. Customers can access and use these resources on-demand and only pay for what they use.
This allows organizations to have the ability to scale their computing resources up or down quickly and easily, depending on their needs. Additionally, because the service provider is responsible for the maintenance and upkeep of the infrastructure, customers can focus on their core business operations and not worry about the underlying technology.
CaaS is often used by businesses of all sizes as a cost-effective and flexible way to meet their computing needs. It can also be used to support a wide range of applications, including web and mobile apps, big data and analytics, and even scientific simulations and modeling.
Server
A server is a computer program or device that provides functionality for other programs or devices, called clients. Servers can provide various services, such as serving web pages, hosting email, storing files, processing data, and much more. The clients connect to the server to request these services, and the server responds by performing the requested actions and sending the results back to the client. Servers are typically located on remote computers that can be accessed over a network, such as the Internet, and are designed to run continuously to provide services to multiple clients simultaneously.
Choose the right compute option
Choosing the right compute option for your needs depends on several factors, including:
Workload requirements: The compute option you choose should be able to handle the workloads you want to run, including CPU, memory, storage, and network requirements.
Scalability: You should consider the scalability of the compute option, including how easily you can add or remove resources as your needs change.
Cost: The cost of the compute option, including both the upfront costs and the ongoing costs, should be considered.
Performance: The performance of the compute option should be considered, including the processing power, memory, storage, and network capabilities.
Security: The security of the compute option should be considered, including the measures in place to protect your data and applications from unauthorized access or cyber attacks.
Availability: The availability of the compute option should be considered, including the measures in place to ensure that your applications and data are always available and accessible.
Management: The management and administration of the compute option should be considered, including the ease of use and the resources required to manage and maintain the environment.
Based on these factors, you can choose from several compute options, including:
Physical servers: Physical servers are physical hardware devices that are installed in a data center or on-premises.
Virtual machines: Virtual machines are software-based simulations of physical servers, running on a host server.
Containers: Containers are a lightweight form of virtualization that allow multiple applications to run on a single physical host.
Cloud computing: Cloud computing provides on-demand access to computing resources over the internet, including virtual machines, storage, and networking.
Serverless computing: Serverless computing is a cloud computing model where the cloud provider manages the infrastructure and allocates resources dynamically, only charging for the specific resources used by an application.
Amazon Elastic Compute Cloud
Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides scalable computing capacity in the Amazon Web Services (AWS) cloud. With Amazon EC2, you can launch virtual machines (also known as instances), configure security and networking, and manage storage. You can choose from a variety of operating systems and software packages, and you can use Amazon EC2 to run applications, host websites, process big data, and more.
One of the key benefits of Amazon EC2 is its scalability. You can easily increase or decrease the number of instances you are running, and Amazon EC2 automatically handles the underlying infrastructure, so you don't have to worry about managing hardware.
Another benefit is cost-effectiveness. With Amazon EC2, you only pay for the resources you use, and you can take advantage of Amazon's economies of scale to reduce your costs.
Amazon EC2 is also highly secure, with a variety of security features and options, including network firewalls, encryption of data at rest and in transit, and access control mechanisms.
Overall, Amazon EC2 is a flexible and cost-effective compute option that can be used to support a wide range of use cases, from small startups to large enterprises.
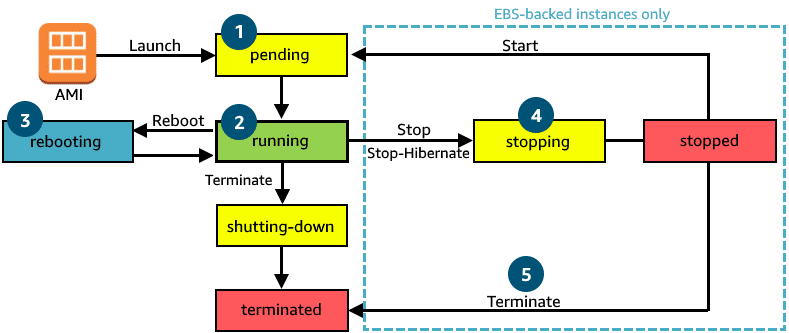
Amazon EC2 Instance Lifecycle
The lifecycle of an Amazon EC2 instance typically consists of the following stages:
Launch: An EC2 instance is launched by selecting an Amazon Machine Image (AMI) that defines the operating system and software packages to be installed on the instance. You can configure the instance type, security groups, storage, and other options before launching the instance.
Running: Once the instance is launched, it is in a "running" state, and you can connect to it, install additional software, configure it, and run applications on it.
Stopping: You can stop a running instance if you need to temporarily shut it down. A stopped instance retains its data and configuration, but it is no longer running and cannot be accessed.
Starting: You can start a stopped instance when you are ready to use it again. The instance returns to a "running" state, and you can connect to it and resume your work.
Terminating: You can terminate an EC2 instance if you no longer need it. Terminating an instance permanently removes it from your AWS account, and any data stored on the instance is lost.
Snapshotting: You can create a snapshot of an EC2 instance, which is a point-in-time copy of the instance's data. Snapshots can be used to back up your data, restore instances, or create new instances based on the snapshot.
Rebooting: You can reboot an EC2 instance if you need to restart the operating system or resolve issues with the instance. Rebooting an instance does not result in data loss or changes to the instance's configuration.
Overall, the lifecycle of an EC2 instance is designed to be flexible and allow you to easily manage your computing resources as your needs change. You can launch, stop, start, terminate, snapshot, and reboot instances as needed to support your applications and workloads.
Amazon EC2 instance types
Amazon EC2 offers a variety of instance types, each designed to meet specific computing requirements. The different instance types differ in terms of the number of virtual CPUs (vCPUs), amount of memory, storage options, and network performance. Some of the most commonly used EC2 instance types include:
General Purpose:
t2: Entry-level instances with a balance of compute, memory, and network resources.
m5: Performance optimized instances with a balanced ratio of CPU, memory, and network resources.
m6g: New generation of general purpose instances with high-performance Arm-based processors.
Compute Optimized:
c5: Instances optimized for compute-intensive workloads with a high ratio of CPU to memory.
c6g: New generation of compute-optimized instances with high-performance Arm-based processors.
Memory Optimized:
r5: Instances optimized for memory-intensive workloads with a high ratio of memory to CPU.
z1d: High-performance instances with low latency and high memory bandwidth.
Storage Optimized:
d2: Instances optimized for high-performance, high-capacity storage workloads.
h1: Instances optimized for high-performance storage-intensive workloads.
GPU instances:
- g4: Instances designed for GPU-accelerated applications such as video encoding, 3D rendering, and scientific modeling.
ARM instances:
- a1: Cost-optimized instances powered by Arm-based processors.
You can choose the right instance type for your needs based on the performance, storage, and networking requirements of your applications. Amazon EC2 also provides the ability to resize instances, so you can easily adjust your computing resources as your needs change.
Container Services
AWS Container Services provide scalable and highly available services for running and managing containerized applications. The services allow you to deploy, manage, and scale containerized applications using different container technologies, including Docker and Kubernetes. The following are the main AWS Container Services:
Amazon Elastic Container Service (ECS): Amazon ECS is a fully managed container orchestration service that makes it easy to run, scale, and secure Docker containers on Amazon EC2 instances. With ECS, you can easily deploy containerized applications, manage task scheduling, and monitor and troubleshoot containerized workloads.
Amazon Elastic Kubernetes Service (EKS): Amazon EKS is a fully managed service that makes it easy to run Kubernetes on AWS. EKS provides a highly available and scalable Kubernetes control plane and integrates with other AWS services for security, networking, and storage. With EKS, you can deploy, manage, and scale containerized applications using Kubernetes.
AWS Fargate: AWS Fargate is a serverless compute engine for containers that allows you to run containers without having to manage the underlying infrastructure. With Fargate, you can deploy containers on-demand, pay only for the resources you use, and scale your applications automatically.
AWS App Runner: AWS App Runner is a fully managed service that makes it easy to build, deploy, and run containerized applications. App Runner provides an intuitive interface for developers to create containerized applications and automatically builds and deploys the applications for you.
AWS Container Services provide a variety of options for deploying and managing containerized applications, making it easy for developers to focus on their applications rather than the underlying infrastructure. Whether you're running simple or complex containerized workloads, AWS Container Services can help simplify the management and scaling of your applications.
Docker
When you hear the word container, you might associate it with Docker. Docker is a popular container runtime that simplifies the management of the entire operating system stack needed for container isolation, including networking and storage. Docker helps customers create, package, deploy, and run containers.
Serverless
Serverless computing is a cloud computing model that allows developers to build and run applications without managing the underlying infrastructure. In a serverless architecture, the cloud provider automatically manages the server and infrastructure needed to run the application. The application is broken down into small, stateless functions that are executed on-demand in response to events or triggers.
The key benefits of serverless computing include:
Reduced operational complexity: With serverless computing, developers don't have to manage the underlying infrastructure, servers, or operating systems. This can help to reduce operational complexity, minimize the need for IT support, and increase development speed.
Automatic scaling: Serverless computing automatically scales up or down in response to changes in demand. This means that resources are allocated only when needed, resulting in lower costs and more efficient use of resources.
Pay-per-use pricing: Serverless computing allows you to pay only for the time that your application code runs, not for idle infrastructure. This can result in significant cost savings for applications with variable workloads.
Faster time-to-market: Serverless computing can help developers get their applications to market faster by reducing the time needed for infrastructure setup and management.
High availability: Serverless computing is designed for high availability, so your applications can easily recover from failures.
Some popular serverless computing services provided by AWS include AWS Lambda, Amazon API Gateway, and AWS Step Functions. Other cloud providers, such as Microsoft Azure and Google Cloud Platform, also offer their own serverless computing services.
Overall, serverless computing provides a flexible and cost-effective way to build and run applications, allowing developers to focus on building business logic without worrying about infrastructure management.
AWS Lambda
AWS Lambda is a serverless compute service provided by Amazon Web Services (AWS) that allows developers to run code without provisioning or managing servers. With Lambda, you can run code in response to events or triggers, such as changes to data in Amazon S3, API requests made through Amazon API Gateway, or messages sent through Amazon SNS.
Lambda supports a wide variety of programming languages, including Node.js, Java, C#, Python, Go, and Ruby, and you can use the AWS Management Console, CLI, or SDKs to create and manage your Lambda functions.
Some of the key benefits of using Lambda include:
Serverless: With Lambda, you don't have to worry about servers, operating systems, or infrastructure management. AWS automatically manages the underlying infrastructure, including scaling and security, so you can focus on your code.
Scalable: Lambda automatically scales your code in response to changes in demand, ensuring that you have enough resources to handle any workload.
Event-driven: Lambda can be triggered by a wide range of events, allowing you to build highly responsive and scalable applications.
Cost-effective: With Lambda, you only pay for the time that your code runs, with no upfront costs or minimum fees. This makes it a highly cost-effective way to run your code.
Integrated with other AWS services: Lambda can be easily integrated with other AWS services, including Amazon S3, Amazon DynamoDB, and Amazon Kinesis, allowing you to build complex applications with ease.
Overall, AWS Lambda provides a flexible and scalable way to run your code, allowing you to build highly responsive and cost-effective applications.
Choose the Right Compute Service
Networking
Networking defined
Networking is how you connect computers around the world and allow them to communicate with one another. In this course, you’ve already seen a few examples of networking. One is the AWS Global Infrastructure. AWS built a network of resources using data centers, Availability Zones, and Regions.
IP addresses
To properly route your messages to a location, you need an address. Just like each home has a mailing address, each computer has an IP address. However, instead of using the combination of street, city, state, zip code, and country, the IP address uses a combination of bits, 0s and 1s. Here is an example of a 32-bit address in binary format:
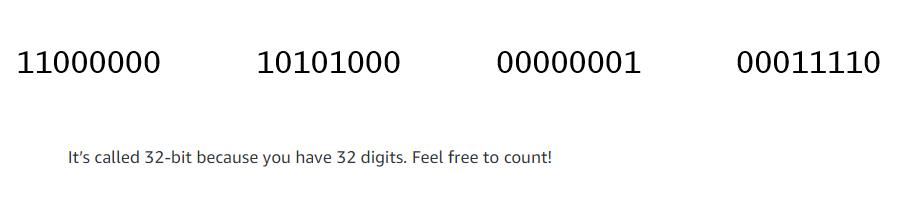
It’s called 32-bit because you have 32 digits. Feel free to count!
IPv4 notation
Typically, you don’t see an IP address in its binary format. Instead, it’s converted into decimal format and noted as an Ipv4 address.In the following diagram, the 32 bits are grouped into groups of 8 bits, also called octets. Each of these groups is converted into decimal format separated by a period.

In the end, this is what is called an Ipv4 address. This is important to know when trying to communicate to a single computer. But remember, you’re working with a network. This is where CIDR notation comes in.
CIDR notation
192.168.1.30 is a single IP address. If you want to express IP addresses between the range of 192.168.1.0 and 192.168.1.255, how can you do that?One way is to use Classless Inter-Domain Routing (CIDR) notation. CIDR notation is a compressed way of specifying a range of IP addresses. Specifying a range determines how many IP addresses are available to you.CIDR notation is shown here.

It begins with a starting IP address and is separated by a forward slash (the “/” character) followed by a number. The number at the end specifies how many of the bits of the IP address are fixed. In this example, the first 24 bits of the IP address are fixed. The rest are flexible.
32 total bits subtracted by 24 fixed bits leaves 8 flexible bits. Each of these flexible bits can be either 0 or 1, because they are binary. That means that you have two choices for each of the 8 bits, providing 256 IP addresses in that IP range.The higher the number after the /, the smaller the number of IP addresses in your network. For example, a range of 192.168.1.0/24 is smaller than 192.168.1.0/16.When working with networks in the AWS Cloud, you choose your network size by using CIDR notation. In AWS, the smallest IP range you can have is /28, which provides 16 IP addresses. The largest IP range you can have is a /16, which provides 65,536 IP addresses.
Amazon Web Services (AWS) provides a variety of networking services to enable secure and scalable communication between different resources in the cloud. Here are some of the key AWS networking services:
Amazon Virtual Private Cloud (VPC): VPC allows you to create a private network in the AWS cloud that is isolated from the public internet. You can create your own IP address range, subnets, and route tables to control traffic within your VPC.
Elastic Load Balancing (ELB): ELB distributes incoming traffic across multiple EC2 instances or containers, helping to increase availability and scalability of your application.
Amazon Route 53: Route 53 is a DNS (Domain Name System) web service that provides routing for incoming traffic to AWS resources, such as EC2 instances, S3 buckets, and load balancers.
AWS Direct Connect: Direct Connect provides a dedicated network connection between your on-premises data center and AWS, allowing you to reduce network costs, increase bandwidth throughput, and provide a more consistent network experience.
AWS Transit Gateway: Transit Gateway simplifies the management of multiple VPCs and VPN connections, by enabling you to connect your VPCs and VPNs to a single gateway.
AWS PrivateLink: PrivateLink allows you to securely access services hosted on AWS, without using public IPs or requiring the traffic to traverse the public internet.
AWS Global Accelerator: Global Accelerator is a service that helps improve the availability and performance of your applications by routing traffic through AWS's global network of edge locations.
These are just a few examples of the many networking services provided by AWS. With these services, you can build highly available and scalable applications in the cloud, while maintaining the security and privacy of your data.
Amazon Virtual Private Cloud
Amazon Virtual Private Cloud (VPC) is a service provided by Amazon Web Services (AWS) that allows you to create your own private, isolated network within the AWS cloud. This enables you to create and control your own virtual network topology, including subnets, route tables, and network gateways.
By using Amazon VPC, you can launch resources such as Amazon Elastic Compute Cloud (EC2) instances, Relational Database Service (RDS) instances, and Elastic Load Balancers (ELBs) within a virtual network of your own design, which is logically isolated from other virtual networks in the AWS cloud. This provides enhanced security and privacy for your applications and data.
Key features of Amazon VPC include:
Network Isolation: You can create multiple virtual networks, or subnets, within a single VPC, allowing you to separate different types of resources and control their access.
IP Address Management: You can assign IP addresses to resources within your VPC, and control access to them using security groups and network access control lists (ACLs).
Routing Control: You can create and manage your own routing tables, enabling you to control the flow of traffic between subnets and to and from the internet.
Network Gateways: You can connect your VPC to other networks, including your on-premises data center, using virtual private network (VPN) or AWS Direct Connect.
Security: You can control access to your resources using security groups and network ACLs, and you can also encrypt traffic between resources within your VPC using Amazon VPC endpoints.
In summary, Amazon VPC provides a flexible and secure way to create your own virtual network within the AWS cloud, giving you complete control over your network topology and enabling you to run your applications securely and with high availability.
An internet gateway is a horizontally scalable, redundant, and highly available AWS service that allows communication between your Amazon Virtual Private Cloud (VPC) and the internet. It provides a target in your VPC route tables for internet-bound traffic, and it performs network address translation (NAT) for instances that have been assigned public IP addresses.
In simple terms, an internet gateway is the gateway that connects your VPC to the public internet. When you create a VPC, it's completely isolated from the public internet. An internet gateway allows traffic to flow between the internet and your VPC.
Once an internet gateway is attached to your VPC, you can configure your VPC route tables to send traffic destined for the public internet to the internet gateway. This allows resources within your VPC, such as Amazon Elastic Compute Cloud (EC2) instances or Amazon RDS databases, to communicate with the internet.
An internet gateway can handle traffic from multiple VPCs and is designed to scale horizontally, allowing it to handle increasing amounts of traffic as your needs grow. It is also highly available, with automatic failover and redundancy built in, ensuring that your traffic continues to flow even in the event of a component failure.
In summary, an internet gateway is a crucial component of a VPC that allows you to connect your resources to the internet, and it enables you to use AWS services, access the internet, and communicate with external resources securely and reliably.
Amazon VPC Routing
Amazon Virtual Private Cloud (VPC) routing allows you to control the flow of traffic within and between subnets within your VPC. When you create a VPC, a default route table is created that allows communication between instances in the VPC and any other instances in the same VPC. However, you can create and manage additional custom route tables to further control traffic within your VPC.
Each subnet within your VPC must be associated with a route table. This association controls the traffic that is allowed in and out of the subnet. You can specify the routing rules for each route table by adding, removing, or modifying routes.
Each route in a route table specifies a destination IP address range and a target. The target can be a network interface, a VPC peering connection, a virtual private gateway, an internet gateway, or a NAT gateway.
For example, you can create a route that directs traffic destined for the internet (0.0.0.0/0) to an internet gateway, which allows resources within your VPC to communicate with the public internet. You can also create routes that direct traffic between subnets in your VPC, or that direct traffic to a VPN connection or a Direct Connect gateway to establish a secure connection to your on-premises data center.
You can control the security of your VPC using security groups and network access control lists (ACLs), which allow you to restrict traffic to and from specific IP addresses and ports.
In summary, Amazon VPC routing provides you with the flexibility to control and secure the flow of traffic within and between subnets in your VPC, and to establish secure connections to external resources using a variety of targets.
Amazon VPC Security
Amazon Virtual Private Cloud (VPC) provides several security features to help you secure your VPC and the resources running within it. Some of the key security features of Amazon VPC are:
Security Groups: Security groups act as a virtual firewall for your instances to control inbound and outbound traffic. You can create security groups to control traffic based on IP protocol, port number, and source and destination IP address.
Network Access Control Lists (NACLs): NACLs act as a firewall for subnets in your VPC. You can create NACL rules to allow or deny traffic based on IP protocol, port number, and source and destination IP address.
Private Subnets: Private subnets allow you to isolate your resources from the internet. By placing your resources in a private subnet, you can control access to them using NAT gateways, VPN connections, or VPC peering.
Virtual Private Network (VPN): VPN allows you to securely connect your on-premises data center to your VPC over an encrypted connection.
AWS PrivateLink: AWS PrivateLink provides private connectivity between VPCs and services without going over the public internet. It allows you to access AWS services such as AWS Lambda or Amazon S3 over private connections within your VPC.
VPC Endpoints: VPC endpoints allow you to securely access AWS services, such as Amazon S3, without requiring traffic to traverse the internet.
Flow Logs: Flow Logs enable you to capture and log information about the IP traffic going to and from network interfaces in your VPC.
By using these security features, you can build a secure and isolated environment for your resources within Amazon VPC. These features help you implement network security controls and enforce security policies, ensuring that your resources are protected from unauthorized access and malicious activities.
What is a NAT
A NAT (Network Address Translation) gateway is a device that allows a network of computers with private IP addresses to communicate with other networks, including the internet. The NAT gateway acts as a mediator between the private network and the internet, translating the private IP addresses of the devices on the network into a public IP address that is visible to the internet.
When a device on the private network wants to access the internet, it sends a request to the NAT gateway, which then forwards the request to the internet on behalf of the private device. The response from the internet is then sent back to the NAT gateway, which translates the public IP address back into the private IP address of the device that made the request, and forwards the response back to the device on the private network.
NAT gateways are commonly used in home and small office networks to enable multiple devices to share a single internet connection, and in cloud computing environments to allow virtual machines to access the internet.
AWS Storage
Storage Types
In AWS, storage services are typically categorized into three categories based on their use case and access pattern:
Object Storage: Object storage is used to store and retrieve large amounts of unstructured data, such as images, videos, backups, and logs. AWS offers Amazon S3 (Simple Storage Service) as its primary object storage service. Amazon S3 is highly scalable, durable, and secure, and it offers a wide range of storage classes that cater to various access patterns and use cases.
Block Storage: Block storage is used to store and retrieve structured data, such as databases and applications. In AWS, Amazon EBS (Elastic Block Store) is the primary block storage service. It provides persistent block storage volumes that can be attached to Amazon EC2 instances.
File Storage: File storage is used to store and retrieve data in a file system format. AWS offers Amazon EFS (Elastic File System) as its primary file storage service. It provides a fully-managed file system that can be accessed by multiple EC2 instances concurrently.
In addition to the above categories, AWS also offers hybrid storage solutions, such as AWS Storage Gateway, which allows on-premises applications to access cloud storage, and AWS Snowball, which allows customers to move large amounts of data into and out of AWS using physical appliances.
Amazon EC2 Instance Storage and Amazon Elastic Block Store
Amazon Elastic Compute Cloud (EC2) is a web service that provides resizable compute capacity in the cloud. EC2 instances are virtual servers that can be launched in the cloud to run applications and services.
When launching an EC2 instance, users can choose the instance type and size that best suits their needs. Depending on the instance type, EC2 instances can come with different types of storage, including instance storage and Elastic Block Store (EBS) volumes.
Instance Storage is directly attached to the EC2 instance and provides temporary block-level storage for applications and data. It is a good choice for applications that require high I/O performance and low-latency storage, such as databases or caches. Instance storage is only available while the EC2 instance is running, and any data stored on it is lost when the instance is stopped or terminated.
On the other hand, Elastic Block Store (EBS) is a block-level storage service that provides persistent, durable, and low-latency storage volumes for EC2 instances. EBS volumes can be attached to an EC2 instance and can persist even after the instance is stopped or terminated. EBS volumes can be backed up and replicated across multiple Availability Zones (AZs) for high availability and disaster recovery.
EBS volumes come in several types, including General Purpose SSD (gp2), Provisioned IOPS SSD (io1), Throughput Optimized HDD (st1), and Cold HDD (sc1). Users can choose the EBS volume type and size that best suits their needs based on the application's performance and storage requirements.
In summary, EC2 Instance Storage is a good choice for temporary and high-performance storage needs, while EBS provides durable, persistent, and low-latency storage that can be used for a variety of workloads.
Snapshot
In AWS, a snapshot is a point-in-time copy of an Amazon Elastic Block Store (EBS) volume. It is a backup of the EBS volume and can be used to create a new EBS volume or to restore an existing volume to a previous state.
When you create an EBS snapshot, AWS takes a copy of the data on the volume and stores it in Amazon S3. The snapshot only includes the blocks on the volume that have been modified since the last snapshot was taken, which means that subsequent snapshots only store the incremental changes made to the volume.
EBS snapshots are stored in Amazon S3, which provides high durability, availability, and scalability. Snapshots can be copied to different regions for disaster recovery or migrated to a different AWS account.
EBS snapshots can be used for a variety of use cases, including data backup and disaster recovery, creating new EBS volumes, and migrating data to a new region or account. By taking regular EBS snapshots, users can protect their data and ensure that they can recover their systems and applications in case of a disaster or data loss event.
It is important to note that EBS snapshots are charged based on the amount of data stored in S3, and the frequency of snapshots can affect the storage cost. Therefore, it is recommended to plan the snapshot strategy based on the application's data protection needs and cost considerations.
Amazon EBS use cases
Amazon EBS is useful when you must retrieve data quickly and have data persist long-term. Volumes are commonly used in the following scenarios.
Operating systems: Boot/root volumes to store an operating system. The root device for an instance launched from an Amazon Machine Image (AMI) is typically an Amazon EBS volume. These are commonly referred to as EBS-backed AMIs.
Databases: A storage layer for databases running on Amazon EC2 that rely on transactional reads and writes.
Enterprise applications: Amazon EBS provides reliable block storage to run business-critical applications.
Throughput-intensive applications: Applications that perform long, continuous reads and writes.
Amazon EBS benefits
Here are the benefits of using Amazon EBS.
High availability: When you create an EBS volume, it is automatically replicated in its Availability Zone to prevent data loss from single points of failure.
Data persistence: The storage persists even when your instance doesn’t.
Data encryption: All EBS volumes support encryption.
Flexibility: EBS volumes support on-the-fly changes. You can modify volume type, volume size, and input/output operations per second (IOPS) capacity without stopping your instance.
Backups: Amazon EBS provides the ability to create backups of any EBS volume.
Object Storage with Amazon Simple Storage Service
Amazon Simple Storage Service (S3) is an object storage service that provides a scalable, durable, and highly available storage infrastructure for storing and retrieving any amount of data from anywhere on the web.
Object storage is ideal for storing large volumes of unstructured data, such as media files, backups, log files, and other content that doesn't fit well into a traditional file system. In S3, each object can be up to 5 terabytes in size and can be stored in a bucket, which is a container for storing objects.
S3 provides various features that make it a popular choice for object storage, including:
Durability and availability: S3 provides a highly durable and available storage infrastructure that is designed to withstand the loss of data in a single facility or device. S3 replicates objects across multiple availability zones (AZs) within a region to ensure high availability and durability.
Scalability: S3 can scale to meet any storage need, from a few gigabytes to petabytes of data, without requiring any upfront investments in hardware or infrastructure.
Security: S3 provides several security features, including encryption, access control, and auditing, to protect data stored in the service.
Lifecycle policies: S3 provides lifecycle policies that allow users to automate the transition of objects to different storage classes or delete them based on the age of the objects.
Versioning: S3 provides versioning for objects, which allows users to keep multiple versions of an object and recover from accidental deletions or modifications.
S3 provides various storage classes, including Standard, Standard-Infrequent Access (Standard-IA), One Zone-Infrequent Access (One Zone-IA), Intelligent-Tiering, Glacier, and Glacier Deep Archive. Each storage class has different pricing, durability, and retrieval times, making it easy to choose the right storage class based on the application's access patterns and cost requirements.
In summary, Amazon S3 is a cost-effective and scalable solution for storing and managing large volumes of unstructured data, providing a durable, available, and secure storage infrastructure.
Amazon Elastic File System (Amazon EFS) and Amazon FSx
In this module, you’ve already learned about Amazon S3 and Amazon EBS. You learned that S3 uses a flat namespace and isn’t meant to serve as a standalone file system. You also learned most EBS volumes can only be attached to one EC2 instance at a time. So, if you need file storage on AWS, which service should you use?
For file storage that can mount on to multiple EC2 instances, you can use Amazon Elastic File System (Amazon EFS) or Amazon FSx. The following table provides more information about each service.
Databases in AWS
Amazon Web Services (AWS) offers a range of database services that can be used to store and manage data in the cloud. Here are some of the databases on AWS:
Amazon Relational Database Service (RDS): Amazon RDS is a managed service that provides pre-configured instances of popular relational databases like MySQL, PostgreSQL, Oracle, and Microsoft SQL Server. RDS handles tasks like backups, software patching, and database scaling, making it easier to manage databases.
Amazon Aurora: Aurora is a MySQL and PostgreSQL-compatible relational database that is designed to be highly scalable and performant. Aurora is designed to be compatible with the open-source databases, which means that you can easily migrate existing MySQL and PostgreSQL databases to Aurora.
Amazon DynamoDB: DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance. DynamoDB is a good choice for applications that require low-latency data access and high scalability.
Amazon DocumentDB: DocumentDB is a fully managed document database service that is compatible with MongoDB. DocumentDB provides automatic scalability, backup and restore, and continuous monitoring.
Amazon Neptune: Neptune is a fully managed graph database service that is designed for applications that require high-performance graph queries. Neptune supports open-source graph APIs like Apache TinkerPop and Gremlin.
Amazon ElastiCache: ElastiCache is a fully managed in-memory data store that is compatible with popular open-source data stores like Redis and Memcached. ElastiCache is designed to improve the performance of web applications by reducing database load.
These are just a few of the databases on AWS. AWS offers a range of other database services like Amazon QLDB (a ledger database), Amazon Timestream (a time-series database), and Amazon Redshift (a data warehouse). The choice of database service will depend on factors like data model, performance requirements, scalability, and cost.
Relational database benefits
Relational databases offer a number of benefits, including the following:
Joins: You can join tables, enabling you to better understand relationships between your data.
Reduced redundancy: You can store data in one table and reference it from other tables instead of saving the same data in different places.
Familiarity: Relational databases have been a popular choice since the 1970s. Due to this popularity, technical professionals often have familiarity and experience with this type of database.
Accuracy: Relational databases ensure that your data is persisted with high integrity and adheres to the atomicity, consistency, isolation, durability (ACID) principle.
Amazon Relational Database Service
Amazon Relational Database Service (Amazon RDS) is a fully managed relational database service offered by Amazon Web Services (AWS). It allows users to easily create, operate, and scale a relational database in the cloud.
Amazon RDS supports six different database engines: Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server. Users can choose the engine that best fits their needs and manage their databases using standard SQL queries.
Amazon RDS takes care of the administrative tasks of database management, such as patching, backup, recovery, and scaling, allowing users to focus on their applications instead of worrying about infrastructure. It also offers features such as automated backups, multi-Availability Zone deployments for high availability, and read replicas for scaling read-heavy workloads.
Amazon RDS is a pay-as-you-go service, and users only pay for the resources they use. They can also choose to use reserved instances to save costs on long-term usage.
Amazon DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service provided by Amazon Web Services (AWS). It is designed to provide fast and predictable performance with seamless scalability for high-traffic web applications.
DynamoDB is a key-value and document database that provides a flexible data model, enabling users to store and retrieve data in any format, including structured, semi-structured, and unstructured data. It also supports both document and key-value data models.
DynamoDB offers automatic scalability with no downtime or performance degradation, which allows users to seamlessly increase or decrease their provisioned throughput capacity as their application's demand changes. It also supports backup and restore, point-in-time recovery, and cross-region replication for disaster recovery and high availability.
DynamoDB is fully managed, which means that AWS takes care of all the infrastructure, provisioning, and maintenance tasks. This allows users to focus on building their applications and improving their business logic rather than managing their database infrastructure.
DynamoDB is a pay-as-you-go service, and users only pay for the resources they use. They can also choose to use reserved capacity to save costs on long-term usage.
Amazon DynamoDB core components
In DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to uniquely identify each item in a table and secondary indexes to provide more querying flexibility.
The following are the basic DynamoDB components:
Tables – Similar to other database systems, DynamoDB stores data in tables. A table is a collection of data. For instance, you could have a table called People that you could use to store personal contact information about friends, family, or anyone else of interest. You could also have a Cars table to store information about vehicles that people drive.
Items – Each table contains zero or more items. An item is a group of attributes that is uniquely identifiable among all the other items. In a People table, each item represents a person. In a Cars table, each item represents one vehicle. Items in DynamoDB are similar in many ways to rows, records, or tuples in other database systems. In DynamoDB, there is no limit to the number of items you can store in a table.
Attributes – Each item is composed of one or more attributes. An attribute is a fundamental data element, something that does not need to be broken down any further. For example, an item in a People table might contain attributes called PersonID, LastName, FirstName, and so on. In a Department table, an item might have attributes such as DepartmentID, Name, Manager, and so on. Attributes in DynamoDB are similar in many ways to fields or columns in other database systems.
Choose the Right Database Service
Choosing the right database service depends on a variety of factors, including the type of application you are building, the amount and type of data you need to store and manage, the performance and scalability requirements of your application, and your budget.
Here are some guidelines to help you choose the right database service:
Relational databases: If you have structured data with complex relationships and transactions, consider using a relational database such as Amazon RDS, which provides a fully managed relational database service.
NoSQL databases: If you have semi-structured or unstructured data, or you need to store and retrieve data at high speeds, consider using a NoSQL database such as Amazon DynamoDB, which provides a fully managed NoSQL database service.
Big data processing: If you need to process large volumes of data and perform complex analytics, consider using a big data processing service such as Amazon EMR, which provides a fully managed Hadoop and Spark service.
Data warehousing: If you need to store and analyze large amounts of structured data, consider using a data warehousing service such as Amazon Redshift, which provides a fully managed petabyte-scale data warehouse service.
Graph databases: If you need to analyze and store graph data, consider using a graph database such as Amazon Neptune, which provides a fully managed graph database service.
Budget: Consider your budget and cost requirements when choosing a database service. AWS provides several cost-effective options, including free tier services for small-scale applications and reserved capacity options for long-term usage.
In summary, choosing the right database service depends on your specific requirements and the type of application you are building. AWS provides a wide range of fully managed database services that can meet the needs of almost any application.
| Database Type | Use Cases | AWS Service |
| Relational Database | Applications with structured data, transactional workloads, and complex queries | Amazon RDS |
| Non-Relational Database | Applications with unstructured data, high-scale requirements, and fast reads and writes | Amazon DynamoDB |
| In-memory Database | Applications with high-performance needs and real-time data processing | Amazon ElastiCache |
| Graph Database | Applications with complex relationships between data points, such as social networks and recommendation engines | Amazon Neptune |
| Time-series Database | Applications with high volumes of time-stamped data, such as IoT and monitoring applications | Amazon Timestream |
| Document Database | Applications with semi-structured data, such as user profiles and product catalogs | Amazon DocumentDB |
| Ledger Database | Applications that require an immutable and tamper-evident transaction log, such as supply chain management and financial systems | Amazon QLDB |
Monitoring Optimization and Serverless
Application Management
Monitoring
AWS (Amazon Web Services) provides several tools and services for monitoring your applications and infrastructure on its cloud platform. Here are some of the key offerings:
Amazon CloudWatch: A monitoring and observability service that provides metrics and logs for AWS resources and applications. CloudWatch can be used to collect and track metrics, collect and monitor log files, and set alarms.
AWS CloudTrail: A service that provides a record of API calls made in your AWS account. CloudTrail helps you identify changes made to resources and understand how and when resources were created, modified, or deleted.
Amazon GuardDuty: A threat detection service that continuously monitors for malicious activity and unauthorized behavior in your AWS account. GuardDuty uses machine learning to analyze data from AWS CloudTrail, VPC Flow Logs, and DNS logs to identify potential threats.
AWS Config: A service that provides a detailed inventory of your AWS resources and their configurations. Config can be used to track changes and compliance across your resources, and it can also be used to trigger automated remediation actions.
AWS X-Ray: A service that helps you debug and analyze distributed applications. X-Ray provides a visual representation of the request flow through your application, and it can be used to identify performance issues and errors.
Amazon S3 Inventory: A service that provides reports on the objects stored in your Amazon S3 buckets. S3 Inventory can be used to monitor and manage the lifecycle of objects in your S3 buckets, and it can help you comply with regulatory and business requirements.
Overall, AWS provides a range of services that can help you monitor and observe your applications and infrastructure in the cloud, from collecting metrics and logs to detecting and responding to potential security threats.
Monitoring benefits
Monitoring gives you visibility into your resources, but the question now is, "Why is that important?" This section describes some of the benefits of monitoring.
Respond to operational issues proactively before your end users are aware of them. Waiting for end users to let you know when your application is experiencing an outage is a bad practice. Through monitoring, you can keep tabs on metrics like error response rate and request latency. Over time, the metrics help signal when an outage is going to occur. This enables you to automatically or manually perform actions to prevent the outage from happening, and fix the problem before your end users are aware of it.
Improve the performance and reliability of your resources. Monitoring the various resources that comprise your application provides you with a full picture of how your solution behaves as a system. Monitoring, if done well, can illuminate bottlenecks and inefficient architectures. This helps you drive performance and improve reliability.
Recognize security threats and events. When you monitor resources, events, and systems over time, you create what is called a baseline. A baseline defines what activity is normal. Using a baseline, you can spot anomalies like unusual traffic spikes or unusual IP addresses accessing your resources. When an anomaly occurs, an alert can be sent out or an action can be taken to investigate the event.
Make data-driven decisions for your business. Monitoring keeps an eye on IT operational health and drives business decisions. For example, suppose you launched a new feature for your cat photo app and now you want to know if it’s being used. You can collect application-level metrics and view the number of users who use the new feature. With your findings, you can decide whether to invest more time into improving the new feature.
Create more cost-effective solutions. Through monitoring, you can view resources that are being underused and rightsize your resources to your usage. This helps you optimize cost and make sure you aren’t spending more money than necessary.
Amazon CloudWatch is a monitoring and observability service that collects data like those mentioned in this module. CloudWatch provides actionable insights into your applications, and enables you to respond to system-wide performance changes, optimize resource usage, and get a unified view of operational health.
You can use CloudWatch to:
Detect anomalous behavior in your environments
Set alarms to alert you when something is not right
Visualize logs and metrics with the AWS Management Console
Take automated actions like scaling
Troubleshoot issues
Discover insights to keep your applications healthy
Amazon CloudWatch is a monitoring and observability service provided by AWS (Amazon Web Services) that provides real-time monitoring and visibility into your AWS resources, applications, and services. Here are some key features of Amazon CloudWatch:
Metrics: CloudWatch collects and tracks metrics, such as CPU utilization, network traffic, and disk usage, for your AWS resources and applications. You can use these metrics to monitor the performance and health of your resources and trigger alarms when certain thresholds are exceeded.
Logs: CloudWatch can also be used to collect, monitor, and analyze logs from your AWS resources and applications. You can use CloudWatch Logs to store and analyze log data in a central location, and you can also use CloudWatch Logs Insights to search and analyze log data in real-time.
Alarms: CloudWatch alarms allow you to monitor metrics and send notifications or take automated actions when certain thresholds are exceeded. For example, you can set an alarm to trigger when CPU utilization on an EC2 instance exceeds a certain percentage.
Dashboards: CloudWatch dashboards allow you to create customizable visualizations of your metrics and alarms. You can use dashboards to monitor the health of your resources and applications at a glance.
Events: CloudWatch Events allows you to automate actions in response to changes in your AWS resources and applications. For example, you can use CloudWatch Events to trigger an AWS Lambda function when a new EC2 instance is launched.
Overall, Amazon CloudWatch is a powerful tool for monitoring and observability in the cloud, providing real-time insights into your AWS resources and applications and enabling you to take proactive actions to ensure the health and performance of your infrastructure.
Traffic Routing with Amazon Elastic Load Balancing
Amazon Elastic Load Balancing (ELB) is a service provided by AWS (Amazon Web Services) that automatically distributes incoming application traffic across multiple targets, such as Amazon EC2 instances, containers, and IP addresses. One of the key features of ELB is its ability to perform traffic routing, which allows you to control how incoming traffic is distributed across your targets. Here are some key aspects of traffic routing with Amazon Elastic Load Balancing:
Routing Algorithms: ELB supports several routing algorithms that determine how incoming traffic is distributed across your targets. These include round robin, least outstanding requests, and IP hash routing. You can choose the algorithm that best meets your application's needs.
Target Groups: With ELB, you can group your targets into logical units called target groups. Each target group can be associated with one or more listeners, which specify the protocol and port used to route traffic to the targets.
Path-Based Routing: ELB can also perform path-based routing, which allows you to route traffic based on the URL path. For example, you can route traffic for requests to /api to a different target group than traffic for requests to /web.
Weighted Routing: ELB supports weighted routing, which allows you to distribute traffic across your targets based on a weight assigned to each target. This can be useful when you want to distribute traffic unevenly across targets based on their capacity or other factors.
Canary Release: ELB can also be used to perform canary releases, which involve gradually rolling out new application versions to a subset of users or traffic. With ELB, you can route a small percentage of traffic to a new version of your application, and gradually increase the percentage over time.
Overall, Amazon Elastic Load Balancing provides a flexible and powerful way to perform traffic routing in the cloud, allowing you to distribute incoming traffic across your targets based on a variety of criteria and perform canary releases and other advanced deployment strategies.
Amazon EC2 Auto Scaling
Amazon Elastic Compute Cloud (EC2) Auto Scaling is a service provided by Amazon Web Services (AWS) that automatically adjusts the number of EC2 instances running in response to changes in demand for an application or workload.
EC2 Auto Scaling allows you to create and manage groups of EC2 instances that can automatically scale up or down based on certain conditions. These conditions can be based on metrics such as CPU utilization, network traffic, or custom metrics.
When the demand for an application or workload increases, EC2 Auto Scaling can automatically launch additional instances to handle the increased load. When the demand decreases, it can automatically terminate instances to reduce costs.
EC2 Auto Scaling provides a variety of benefits, including improved availability, better performance, and reduced costs. By automatically scaling up or down based on demand, EC2 Auto Scaling helps ensure that your application can handle traffic spikes without requiring manual intervention. This can help improve the overall user experience and reduce the risk of downtime or performance issues. Additionally, by only running the instances that are needed, EC2 Auto Scaling can help reduce your AWS costs.
Conclusion
AWS offers a wide range of web services that can help businesses of all sizes build and deploy applications in the cloud. Each of the topics we covered - AWS compute, networking, storage, databases, monitoring optimization, and serverless - plays a critical role in enabling organizations to create scalable and cost-effective cloud solutions.
AWS compute services, such as EC2 and Lambda, provide a flexible and powerful platform for running applications and services, while AWS networking services, including VPC and Direct Connect, enable organizations to securely connect their on-premises resources to the cloud.
AWS storage services, such as S3 and EBS, offer a durable and scalable solution for storing and retrieving data, while AWS databases services, such as RDS and DynamoDB, provide a managed database platform that enables organizations to build scalable and highly available applications.
Monitoring optimization is another important aspect of AWS, as it allows organizations to monitor and optimize their cloud resources for cost, performance, and security. Finally, AWS serverless services, such as AWS Lambda and AWS API Gateway, enable developers to build and deploy applications without having to worry about infrastructure management.
Overall, AWS web services offer a powerful and flexible platform for organizations to build and deploy applications in the cloud. By leveraging the various AWS services for compute, networking, storage, databases, monitoring optimization, and serverless, organizations can create scalable and cost-effective solutions that meet their specific needs. With AWS, businesses can unlock new opportunities for innovation and growth, while also improving efficiency and reducing costs.




